
You may be familiar with the long-running divide between Classical or Frequentist (a.k.a. Neyman-Pearson) and Bayesian statisticians. (If not, here’s a simplistic overview.) The schism is being smoothed over, and many statisticians I know are pragmatists who feel free to use either approach depending on the problem at hand.
However, when I read Gerard van Belle’s Statistical Rules of Thumb, I was surprised by his brief mention of three distinct schools of inference: Neyman-Pearson, Bayesian, and Likelihood. I hadn’t heard of the third, so I followed van Belle’s reference to Michael Oakes’ book Statistical Inference: A Commentary for the Social and Behavioural Sciences.
Why should you care what school of inference you use? Well, it’s a framework that guides how you think about science: this includes the methods you choose to use and, crucially, how you interpret your results. Many Frequentist methods have a Bayesian analogue that will give the same numerical result on any given dataset, but the implications you can draw are quite different. Frequentism is the version taught traditionally in Stat101, but if you show someone the results of your data analysis, most people’s interpretation will be closer to the Bayesian interpretation than the Frequentist. So I was curious how “Likelihood inference” compares to these other two.
Below I summarize what I learned from Oakes about Likelihood inference. I close with some good points from the rest of Oakes’ book, which is largely about the misuse of null hypothesis significance testing (NHST) and a suggestion to publish effect size estimates instead.
What’s “Likelihood inference”? Is it still in use?
Unfortunately Oakes spends only three pages on Likelihood inference so I am still fuzzy on the details. Apparently:
- Like other Frequentists, Likelihoodists are uncomfortable with pure Bayesians’ use of subjective priors and their focus on internal coherence rather than empirical calibration to reality.
- On the other hand, like Bayesians, Likelihoodists see pure Neyman-Pearson inference as logically consistent but irrelevant: a scientist wants to talk about the plausibility of a scientific hypothesis, not about long-run error rates of decisions regarding repeated samples under similar conditions: “classical statistics evades the problem that is at the heart of scientific discovery […] The Neyman-Pearson emphasis upon decision rules with stated error rates … seems much less relevant to the assessment of scientific hypotheses” (p. 124-125). Furthermore, Neyman-Pearson’s use of tail areas leads to violation of the likelihood principle.
(However, Oakes cites Cornfield 1966 who showed that if Neyman and Pearson had minimized a linear function of type 1 and type 2 errors,, instead of minimizing
for a constant
, the likelihood principle would have been satisfied.)
Instead, Likelihood inference restricts itself to relative support for hypotheses, by way of the likelihood ratio. For instance if the likelihood of 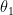
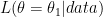
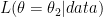
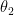
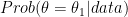
The log of the likelihood is called the “support function”; and differences between supports for
Use the maximum likelihood estimate as your point estimate. To get an interval estimate for 
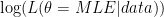
My first thought is that the “plus or minus 2 support units” seems quite ad hoc, though perhaps Edwards or others justify it in more detail than Oakes. [Edit: Apparently is it incorrect; see Mike’s comment below.] Furthermore, restricting yourself to relative support seems like a safe stand to take, but it may be too limiting. Oakes quotes A.W.F. Edwards’ Likelihood: “Though it may seem a little uncharitable to such important branches of statistics, I have little to say about Least Squares, Experimental Design, and the Analysis of Variance.”
Perhaps later authors found more to say, but Oakes’ 1986 book only has references that were already over 10 years old then. Edwards (1972 edition) is the main reference there, but Oakes also quotes some of its main proponents showing disillusionment already by 1975 (Hacking: “Birnbaum has given it up and I have become pretty dubious”). I also can’t find many examples of Likelihood inference in use nowadays: Google Scholar shows 1600-ish citations for Edwards’ book, but on the first few pages of results I saw neither applications nor further theoretical developments of this line of thought.
However, Richard Royall’s Statistical Evidence: A Likelihood Paradigm (1997) seems to be along the same lines; and an Amazon reviewer states that Art Owen’s work on empirical likelihood is the successor to Edwards. So… I have more reading to do.
Finally, Oakes’ discussion of Likelihood inference is in the context of a comparison to Neyman-Pearson, Bayesian, and also Fiducial inference. The latter is R.A. Fisher’s “bold attempt to make the Bayesian omelette without breaking the Bayesian eggs” (Jimmy Savage), has major flaws, and I believe is no longer in serious use anywhere.
[Correction: some people do still work on Fiducial inference — for example, I recently met Jessi Cisewski whose dissertation work was on “Generalized Fiducial Inference.”]
Publish effect size estimates, not p-values
Most of Oakes’ book focuses on conceptual and practical problems with what is now known as the null hypothesis significance testing (NHST) framework under classical Neyman-Pearson inference. There are MANY problems with how this works in practice.
In typical NHST practice, a scientist will take their scientific question of interest (e.g. Does the new teaching method tend to improve kids’ test scores?); turn it into a statistical test of a null hypothesis (The new teaching method has absolutely no effect on the average test score); and publish the resulting p-value. In practice, the authors then conclude that the effect is real if p<0.05 (This new teaching method is indeed better, so let’s switch) or spurious if p>0.05 (Any apparent difference between the teaching methods is due to chance, so let’s stick with the old way).
p. 39: “Type 1 errors never occur!” One immediate problem with NHST (also frequently mentioned by Andrew Gelman among many others) is that the null hypothesis of no effect is almost always surely false from the start. (The two teaching methods must have some difference in effects.) Maybe the difference in effects is so small as to be negligible in practice (scores only improved by 1%), or too small to be worth the cost of switching (scores improved by 10% but the cost of training would still outweigh the benefits), but it’s never truly exactly 0.00000… So for real-world decision-making, we should first consider what effect size is practically significant before we think about statistical significance.
On a related note, many people doing NHST fail to think about the power of their test, i.e. its ability to detect a non-null effect. Oakes, p. 14: “it is far from obvious that keeping
If you don’t know your the power of your tests, it’s likely that real effects are going undetected. Furthermore, replicating a low-power study would give widely different and perhaps conflicting results each time. In other words,
The fact is that you can reject any null hypothesis with a large enough sample (and depending on your experimental design, etc.). The p-value alone does not actually tell you anything about how strong the effect is. All it really tells you is whether your power was high enough (sample was large enough) to confirm that the effect is nonzero. A tiny p-value p<<0.05 could be caused by a very large effect in a small sample, or a very small effect in a large sample. And a large p-value p>>0.05 can result from a small effect in a moderate sample, or from a large effect in a tiny sample. So if you care about effect size, as you should, then the p-value is not a useful summary.
For that matter, a p-value of 0.05 < p < 0.10 does NOT imply a moderately-sized effect! Researchers who get a p-value of 0.07 frequently write something to the effect that people in group A performed “somewhat” better than in group B, but that is not what the p-value implies.
A confidence interval estimate is a much better summary. You get the point estimate of the effect, as well as its plausible range; and if the confidence interval is “unacceptably imprecise” (p. 14), you know the power of the study was too low.
A confidence interval is also particularly useful when a p-value is very close to 0.05. It does not make sense to make very different decisions when p=0.048 vs. when p=0.052. But a confidence interval will simply show that the effect is likely to be near 0 in both cases; and then you can decide for yourself whether its distance from 0 is likely to be large enough to matter in practical terms.
Let me add my two cents to Oakes’ points: our job as statisticians isn’t really to decide whether an effect exists or not, but to give our most precise estimate or prediction of that effect. If you’re working under NHST and get a non-significant test result, and you decide to collect more data until it becomes significant, then that’s bad practice. However, if you just say “The confidence interval is too wide; let me collect more data until it’s precise enough for my needs,” that’s simply being reasonable.
Oakes goes on to document many other strange things people do under the influence of NHST. For example, if the true effect is very small and practically useless, the right practical decision would be to accept the null hypothesis even if it’s really false. That line of thinking has led some people to propose limiting your test’s power and your sample size so that you don’t accept useless hypotheses (p.32)! This is ridiculous — it’s better to publish a confidence interval showing a precise estimate of a very small and practically negligible effect, rather than to limit your power and effectively have a very wide confidence interval such that you don’t know whether the effect is small or large.
Other (notes-to-self)
Section 2.4 lists some scale-free measures of effect size, as alternatives to the confidence interval. These include the standardized difference, the proportion misclassified, and two estimates of “the proportion of variance accounted for”: the squared correlation 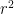
p. 79: People “believe in the ‘law of small numbers’ […] they expect statistics from small samples to lie closer to population parameters than sampling theory allows.” Another case of not considering the power of your experimental or sampling design.
p. 106: “most modern Bayesians […] prefer instead to identify probability with personal uncertainty.” That’s not quite the interpretation I see among people like Gelman, or in David Draper’s idea (via RT Cox and IJ Good) of plausibility to “a generic person wishing to reason sensibly in the presence of uncertainty”… Oakes’ book was published before the computing revolution and MCMC methods made Bayes as tractable and prominent as it is today, and so the people using Bayes then were often doing it for ideological reasons rather than pragmatic.
p. 113: “Neyman and Pearson’s concentration upon the sample space of sample outcomes entails the formulation of the decision rule before the data are collected. It is at this point that decisions as to significance level, sample size, etc. must be taken. This done the ‘inference’ follows automatically.”
Hacking (1965): ‘Thus we infer that the Neyman-Pearson theory is essentially the theory of before-trial betting.'”
This suggests the idea of using N-P to design a good experiment, but then use Bayes to actually analyze data and interpret results. This is similar to the idea of Calibrated Bayes which Rod Little promotes: focus on Bayesian methods which have good long-run Frequentist properties.
p. 157: Of course it’s ideal to do both random sampling and random treatment assignment before you collect the data, but it’s interesting to think about what to do when each is/isn’t true. Here Oakes suggests what each cross-combination implies for the analysis:
- Random sampling from a population and random assignment to treatments: no problem.
- Random sampling from a population but non-random treatment assignment: statistical inference is legit, but causal inference is problematic.
- Complete population census (no sampling) with random treatment assignment: randomization tests are legit.
- Complete population census but non-random assignment: “appeal to a hypothetical universe (Fisher, Hagood) or a random model (Gold) is unhelpful.”
- Neither sampling nor assignment are random: statistical inference is not legit, but “it is argued, statistical analysis is defensible if due regard is paid to the specification of the population and the judged representativeness of the sample.”
Section 7.2 is a take-down of meta-analysis, but his examples from the literature all seem to be rather poorly-done straw-men; surely we do them better nowadays?
p. 166-167: explanation vs. prediction, and laws vs. possibilities:
- The philosophy of science now recognizes that we can explain some things well without being able to predict them (e.g. earthquakes), and vice versa (e.g. child language acquisition). So empirical association isn’t an explanation on its own; but the methods of social science (especially NHST) do not yet reflect this shift.
- “science must be concerned with the discovery and explanation of possibilities as well as with the discovery of putative laws. If, for example, we learn that some children can recite a nursery rhyme backwards the cognitive processes required to perform the feat are worthy of investigation irrespective of the proportion of children who possess the ability.” For such studies, we may not need to focus on statistical inference about population averages as much as qualitative studies on one or two individuals, and that is still legitimate science.
All three inference schools have weaknesses when it comes to putting an interpretation on the results.
Neyman-Pearson tells you exactly what you can say, but it’s not what you care about; adding human judgement to make the results useful is inconsistent with the theory.
Bayes requires you to specify a prior, which bothers Frequentists; but frankly it’s not much worse than the subjectivity Frequentists already use when picking a class of models to start with. And if you do make your prior explicit, then the results are interpretable in the way scientists actually want.
Hi there,
I regularly use likelihood inference in my work, and it is my overall paradigm for inference. If you would like an excellent book on applied likelihood inference and statistical modeling, I would avoid Royall and Edwards, as they are more theoretical/philosophical. Owen is an excellent reference for a particular approach called “Empirical Likelihood” but there is MUCH more to the likelihood school than you will in Owen. I regularly use, and HIGHLY recommend you get a copy of Yudi Pawitan’s “In All Likelihood” — it covers essentiually the ENTIRE range of likelihood theory for applied statistics (and some interesting theoretical/philosophical issues as well). He also uses R extensively, so all his examples are real data and results, not fabricated for easy solutions.
Anyway, thought that I’d recommend that book to you if you are serious about using likelihood theory….the plus/minus two “support units” you cite from Oakes is NOT correct as intervals are formed based on a given normalized likelihood ratio value, not the support value. The theoretical basis for this will become clear if you read Pawitan’s book.
Thank you, Mike. I’m glad to hear likelihood inference is still in active use & development. I will definitely track down a copy of Pawitan’s book. Thanks for the reference!
(Also, sorry for the delay in approving your comment — I’ve been traveling without regular web access.)