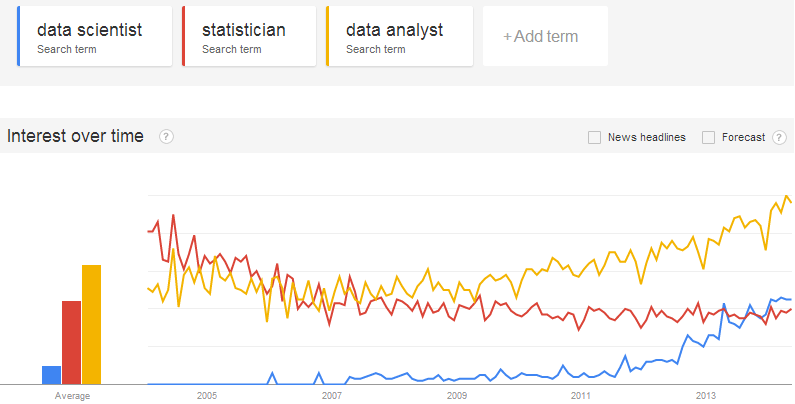
I love having the chance to promote nifty data visualizations; good work from my former employer, the Census Bureau; and student projects from my alma mater, Olin College. So it’s a particular pleasure to highlight all three at once:
Elizabeth Duncan and Marena Richardson, students in Olin’s Data Science course, teamed up with Census staff and BusinessUSA to develop an app that helps make Census data accessible to small business owners.
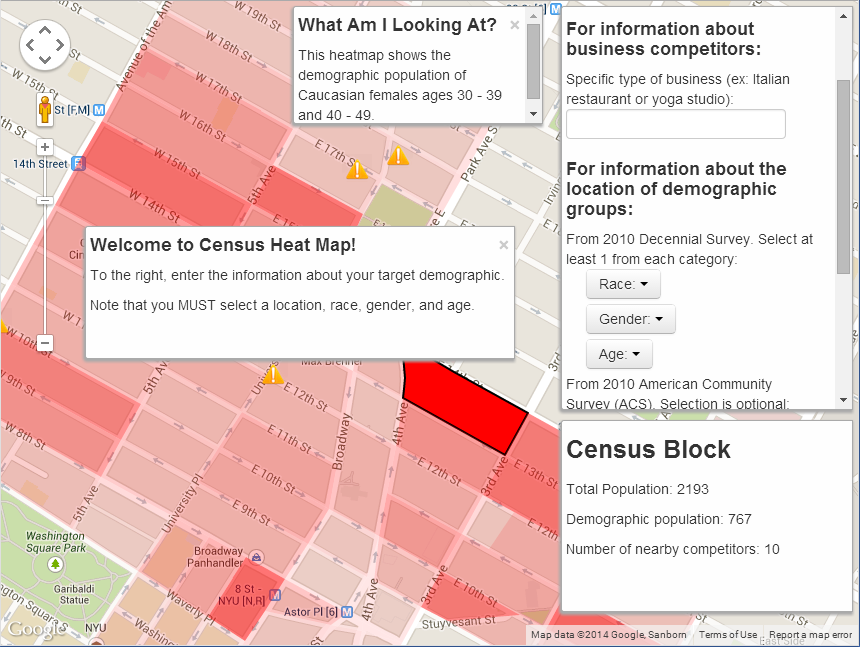
The result, Census Marketing, is a nifty and simple interface to overlay Decennial Census and American Community Survey data on Google Maps.
Imagine you’re planning to start or expand a small business, and you know the demographic you’d like to target (age, income, etc.) Where in your town is there a high concentration of your target market? And, are there already competing businesses nearby?
Load up Duncan and Richardson’s website, enter your location, select demographic categories from a few drop-down menus, and give your business type. The app will go find the relevant data (through the Census API) and display it for you as a block-level heatmap on Google Maps. It’ll also highlight the locations of existing businesses that might be competitors.
For example, say you want to open a pizzeria in my Pittsburgh neighborhood of Squirrel Hill. You might want to target the undergrad and grad student populations, since they tend to order pizza pretty often. Punch in the zip code 15217, choose all races and both sexes, select age groups 20-29 and 30-39, and specify that you’re looking for other competing pizzerias:
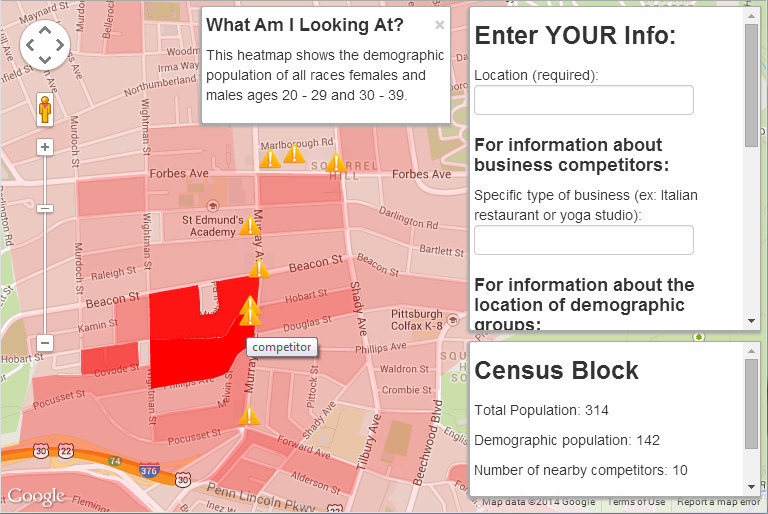
Well! The student-age population is clearly concentrated around Hobart and Murray… but so are the competing pizzerias. Good to know. Maybe you need to brainstorm a new business plan, seek out a different part of town, or try marketing to a different demographic.
Besides learning about data science and creating a website, Duncan and Richardson also interviewed several actual small business owners to refine the user experience. It’s a nice example of Olin’s design-centered approach to engineering education. I can imagine a couple of further improvements to this app… But it’s already a nice use case for the Census API, and a good example of the work Olin students can do in a short time.
PS—the course instructor, Allen Downey, has a free book ThinkStats on introductory statistics from a computer scientist’s point of view. I hear that a revised second edition is on its way.



 ,
,  ,
,  , and
, and  all differ, and why it matters. We saw these concepts last semester in Intermediate Statistics, but the distinctions are far clearer to me now.
all differ, and why it matters. We saw these concepts last semester in Intermediate Statistics, but the distinctions are far clearer to me now.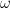 of the set
of the set 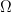 of all possible outcomes or states of the world, to the measurement you will collect (often a number on the real line). Finally, this measure theory view of probability, as the size of a subset of
of all possible outcomes or states of the world, to the measurement you will collect (often a number on the real line). Finally, this measure theory view of probability, as the size of a subset of