Disclaimer: All opinions expressed on this blog are my own and are not intended to represent those of the U.S. Census Bureau.
Edit: Please also read the May 11th official statement responding to the proposed cuts, by Census Bureau Director Robert Groves.
(Again, although of course my opinions are informed by my work with the Bureau, my post below is strictly as a private citizen. I have neither the authority nor the intent to be an official spokesperson for the Census Bureau.)
Yesterday the U.S. House of Representatives voted to eliminate the American Community Survey (ACS). The Senate has not passed such a measure yet. I do not want to get political, but in light of these events it seems appropriate to highlight some of the massive benefits that the ACS provides.
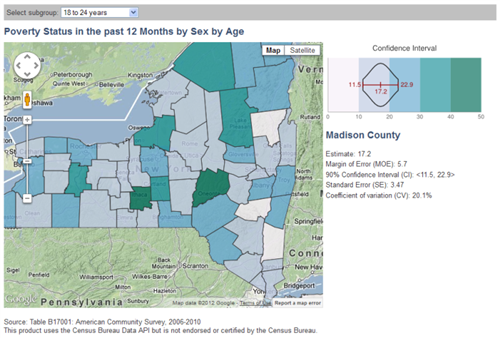
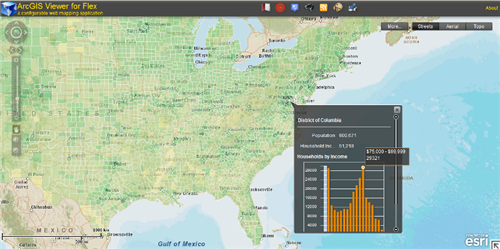
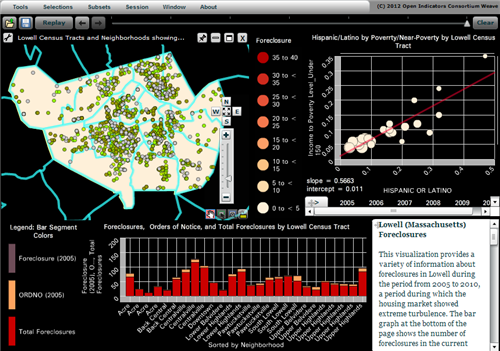
For many variables and indicators, the ACS is the only source of nationally-comparable local data. That is, if you want a detailed look at trends and changes over time, across space, or by demographic group, the ACS is your best dataset for many topics. Take a look at the list of data topics on the right-hand side of the ACS homepage: aging, disability, commuting to work, employment, language, poverty…
Businesses use the ACS to analyze markets: Can people afford our product here? Should we add support for speakers of other languages? Does the aging population here need the same services as the younger population there? Similarly, public health officials use ACS information about population density when deciding where to place a new hospital. Dropping the ACS would increase risks with no corresponding direct benefits to businesses or local governments.
Local authorities can and do commission their own local studies of education levels or commute times; but separate surveys by each area might use incompatible questions. Only the ACS lets them compare such data to their neighbors, to similar localities around the country, and to their own past.
The Census Bureau works long and hard to ensure that each survey is well-designed to collect only the most important data with minimal intrusion. For example, even the flush toilet question (cited deprecatingly by the recent measure’s author) is useful data about infrastructure and sanitation. From the ACS page on “Questions on the form and why we ask”:
Complete plumbing facilities are defined as hot and cold running water, a flush toilet, and a bathtub or shower. These data are essential components used by the U.S. Department of Housing and Urban Development in the development of Fair Market Rents for all areas of the country. Federal agencies use this item to identify areas eligible for public assistance programs and rehabilitation loans. Public health officials use this item to locate areas in danger of ground water contamination and waterborne diseases.
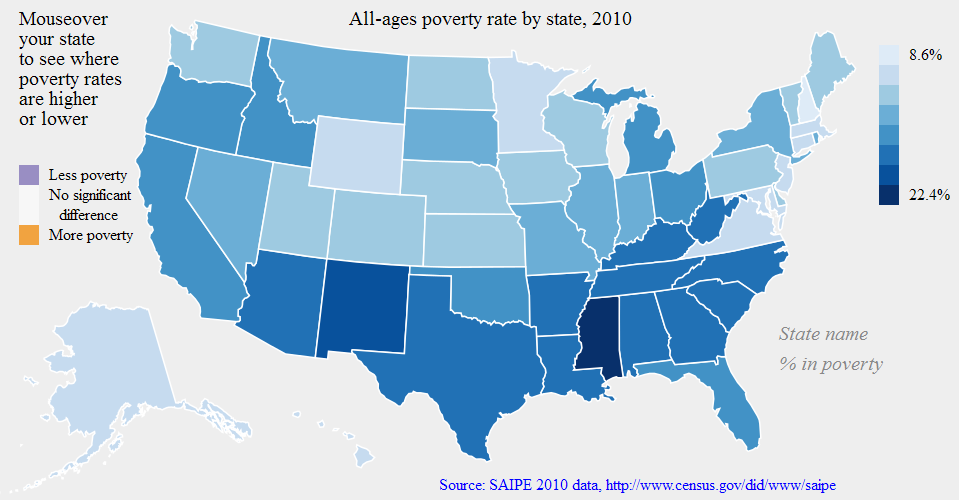
Besides the direct estimates from the ACS itself, the Census Bureau uses ACS data as the backbone of several other programs. For example, the Small Area Income and Poverty Estimates program provides annual data to the Department of Education for use in allocating funds to school districts, based on local counts and rates of children in poverty. Without the ACS we would be limited to using smaller surveys (and thus less accurate information about poverty in each school district) or older data (which can become outdated within a few years, such as during the recent recession). Either way, it would hurt our ability to allocate resources fairly to schoolchildren nationwide.
Similarly, the Census Bureau uses the ACS to produce other timely small-area estimates required by Congressional legislation or requested by other agencies: the number of people with health insurance, people with disabilities, minority language speakers, etc. The legislation requires a data source like the ACS not only so that it can be carried out well, but also so its progress can be monitored.
Whatever our representatives may think about the costs of this survey, I hope they reflect seriously on all its benefits before deciding whether to eliminate the ACS.