I’m preparing “R101,” an introductory workshop on the statistical software R. Perhaps other beginners might find some use in the following summary and resources. (See also the post on resources for teaching yourself introductory statistics.)
Do you have obligatory screenshots of nifty graphics that R can produce? Yes, we do.
Nice. So what exactly is R? It is an open-source software tool for statistics, data processing, data visualization, etc. (Technically there’s a programming language called S, and R is just one open-source software tool that implements the S language. But you’ll often hear people just say “the R language.” Beginners can worry about the nuances later.)
Open source means it is free to download and use; this is great for academics and others with low budgets. It also means you can inspect the code of any algorithm if you want to double-check it or just to see how it’s done; this is great for validating and building on each others’ ideas. And it is easy to share code in user-defined “packages,” of which there are thousands, all helping people use cutting-edge statistical tools as soon as they are invented.
How do I get started? Download and install R from CRAN, the Comprehensive R Archive Network. There are Windows, Mac, and Linux versions.
In Windows at least, when you open the program there is a big window containing a smaller window, the R Console. You can type and submit commands in the Console window at the prompts (the “>” signs). Try typing 3+5 and hit Enter, and you should see the output [1] 8 which is good. The output of 3+5 is a 1-item vector (hence the [1]) with the value 8 as it should be.
Great, now you know how to use R as a desktop calculator!
Or you can type your commands in a script, so that you can save your code easily. Go to “File -> New script” and it will open the R Editor window. Type 3+5 in there, highlight it, and then either click the “Run line or selection” icon on the top menu bar or just hit Ctrl+R on the keyboard. It should copy the command into the Console window and run it, with the same result as before.
Sweet, now you can save the code you used to do your calculations.
Quick-R has more details on using the R interface.
Next, try A Sample Session from the R manual to see examples of other things R can do.
What are the key concepts? Basically, everything is a function or an object. Objects are where your data and results are stored: data frames, matrices, vectors, lists, etc. Functions take objects in, think about them, and spit new objects out. Functions sometimes also have side effects (like displaying a table of output or a graph, or changing a display setting).
If you want to save the results or output of a function, use <- which is the assignment operator (think of an arrow pointing left). For example, to save the natural log of 10 into a variable called x, type the command x <- log(10). Then you can use x as the input to another function.
Note that functions create new output rather than affecting the input variable. If you have a vector called y that you need sorted, sort(y) will print out a sorted copy of y but will not changed y itself. If you actually want y to be sorted, you have to reassign it: y <- sort(y).
Functions always take their input in parentheses: (). So if you see a word followed by parentheses, you know it’s a function in R. You will also see square brackets: []. These are used for locating or extracting data in objects. For example, if you have a vector called y, then y[3] gives you the 3rd element of that vector. If y is a matrix, then y[4,7] is the element in the 4th row, 7th column.
How do I get help? If you know you want to use a function named foo, you can learn more about it by typing ?foo which will bring up the help file for that function. The “Usage” section tells you the arguments, their default order, and their default values. (If no default value is given, it is a required argument.) “Arguments” gives more details about each argument. “Value” gives the structure of the output. “Examples” shows an example of the function in use.
If you know what you want to do but don’t know what the function is called, I suggest looking through the R Reference Card. If that does not answer your question, you can try searching using RSeek.org or search.r-project.org, search engine tuned to the R sites and mailing lists… since just typing the letter R into Google is not always helpful 🙂
Where do I read more?
Online resources for general beginners:
R for Beginners
Simple R
Official Introduction to R
R Fundamentals
Kickstarting R
Let’s Use R Now
UCLA R Class Notes
A Quick and (Very) Dirty Intro to Doing Your Statistics in R
Hints for the R Beginner
R Tutorials from Universities Around the World (88 as of last count)
For statisticians used to other packages:
Quick-R
R for SAS and SPSS Users
For programmers:
R’s unconventional features
Google’s R code style guide
Good books (as suggested by Cosma Shalizi):
Paul Teetor, The R Cookbook: “explains how to use R to do many, many common tasks”
Norman Matloff, The Art of R Programming: “Good introduction to programming for complete novices using R.”



 . I wanted to transport it in a pan with a lid, and I have such a 8″ square pan with surface area
. I wanted to transport it in a pan with a lid, and I have such a 8″ square pan with surface area 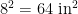 . What’s the best way to fit it in, with the fewest cuts and least wasted scraps? (Well, not really wasted, I’ll eat them gladly 🙂 )
. What’s the best way to fit it in, with the fewest cuts and least wasted scraps? (Well, not really wasted, I’ll eat them gladly 🙂 )