I went to a talk today about Differential Privacy. Unfortunately the talk was rushed due to a late start, so I didn’t quite catch the basic concept. But later I found this nice review paper by Cynthia Dwork who does a lot of research in this area. Here’s a hand-wavy summary for myself to review next time I’m parsing the technical definition.
I’m used to thinking about privacy or disclosure prevention as they do at the Census Bureau. If you release a sample dataset, such as the ACS (American Community Survey)’s PUMS (public use microdata sample), you want to preserve the included respondents’ confidentiality. You don’t want any data user to be able to identify individuals from this dataset. So you perturb the data to protect confidentiality, and then you release this anonymized sample as a static database. Anyone who downloads it will get the same answer each time they compute summaries on this dataset.
(How can you anonymize the records? You might remove obvious identifying information (name and address); distort some data (add statistical noise to ages and incomes); topcode very high values (round down the highest incomes above some fixed level); and limit the precision of variables (round age to the nearest 5-year range, or give geography only at a large-area level). If you do this right, hopefully (1) potential attackers won’t be able to link the released records to any real individuals, and (2) potential researchers will still get accurate estimates from the data. For example, say you add zero-mean random noise to each person’s age. Then the mean age in this edited sample will still be near the mean age in the original sample, even if no single person’s age is correct.)
So we want to balance privacy (if you include *my* record, it should be impossible for outsiders to tell that it’s *me*) with utility (broader statistical summaries from the original and anonymized datasets should be similar).
In the Differential Privacy setup, the setting and goal are a bit different. You (generally) don’t release a static version of the dataset. Instead, you create an interactive website or something, where people can query the dataset, and the website will always add some random noise before reporting the results. (Say, instead of tweaking each person’s age, we just wait for a user to ask for something. One person requests the mean age, and we add random noise to that mean age before we report it. Another user asks for mean age among left-handed college-educated women, and we add new random noise to this mean before reporting it.)
If you do this right, you can get a Differential Privacy guarantee: Whether or not *I* participate in your database has only a small effect on the risk to *my* privacy (for all possible *I* and *my*). This doesn’t mean no data user can identify you or your sensitive information from the data… only that your risk of identification won’t change much whether or not you’re included in the database. Finally, depending on how you choose the noise mechanism, you can ensure this Differential Privacy retains some level of utility: estimates based on these noisified queries won’t be too far from the noiseless versions.
At first glance, this isn’t quite satisfying. It feels in the spirit of several other statistical ideas, such as confidence intervals: it’s tractable for theoretical statisticians to work with, but it doesn’t really address your actual question/concern.
But in a way, Dwork’s paper suggests that this might be the best we can hope for. It’s possible to use a database to learn sensitive information about a person, even if they are not in that database! Imagine a celebrity admits on the radio that their income is 100 times the national median income. Using this external “auxiliary” information, you can learn the celebrity’s income from any database that’ll give you the national median income—even if the celebrity’s data is not in that database. Of course much subtler examples are possible. In this sense, Dwork argues, you can never make *absolute* guarantees to avoid breaching anyone’s privacy, whether or not they are in your dataset, because you can’t control the auxiliary information out there in the world. But you can make the *relative* guarantee that a person’s inclusion in the dataset won’t *increase* their risk of a privacy breach by much.
Still, I don’t think this’ll really assuage people’s fears when you ask them to include their data in your Differentially Private system:
“Hello, ma’am, would you take our survey about [sensitive topic]?”
“Will you keep my responses private?”
“Well, sure, but only in the sense that this survey will *barely* raise your privacy breach risk, compared to what anyone could already discover about you on the Internet!”
“…”
“Ma’am?”
“Uh, I’m going to go off the grid forever now. Goodbye.” [click]
“Dang, we lost another one.”
Manual backtrack: Three-Toed Sloth.

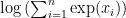 , and you’d like your code to specify the logarithm base explicitly.
, and you’d like your code to specify the logarithm base explicitly.