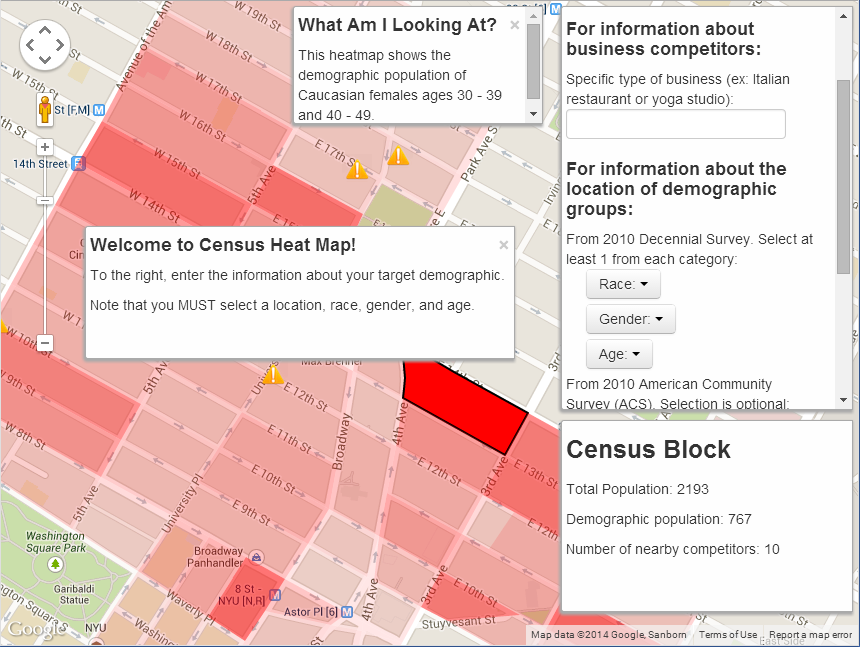
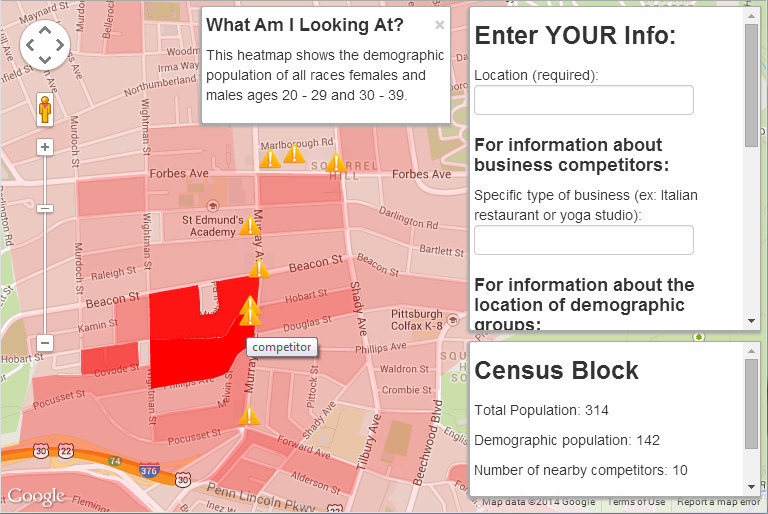
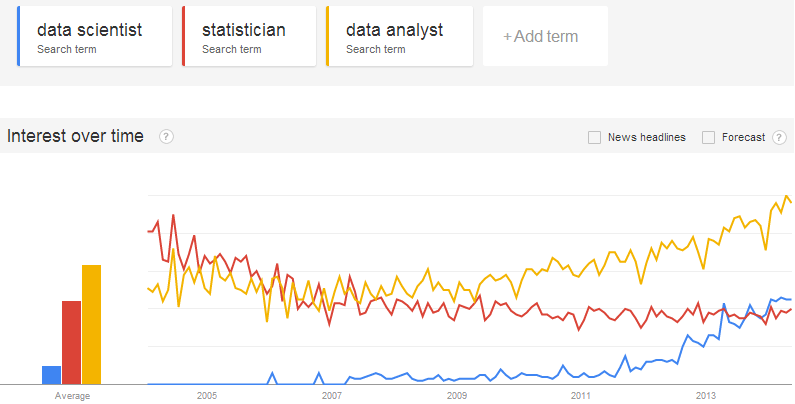
In between project deadlines and homework assignments, I enjoyed taking a break to read Christian Rudder’s Dataclysm. (That’s right, my pleasure-reading break from statistics grad school textbooks is… a different book about statistics. I think I have a problem. Please suggest some good fiction!)
So, Rudder is one of the founders of dating site OkCupid and its quirky, data-driven research blog. His new book is very readable—each short, catchy chapter was hard to put down. I like how he gently alludes to the statistical details for nerds like myself, in a way that shouldn’t overwhelm lay readers. The clean, Tufte-minimalist graphs work quite well and are accompanied by clear writeups. Some of the insights are basically repeats of material already on the blog, but with a cleaner writeup, though there’s plenty of new stuff too. Whether or not you agree with all of his conclusions [edit: see Cathy O’Neil’s valid critiques of the stats analyses here], the book sets a good example to follow for anyone interested in data- or evidence-based popular science writing.
Most of all, I loved his description of statistical precision:
Ironically, with research like this, precision is often less appropriate than a generalization. That’s why I often round findings to the nearest 5 or 10 and the words ‘roughly’ and ‘approximately’ and ‘about’ appear frequently in these pages. When you see in some article that ‘89.6 percent’ of people do x, the real finding is that ‘many’ or ‘nearly all’ or ‘roughly 90 percent’ of them do it, it’s just that the writer probably thought the decimals sounded cooler and more authoritative. The next time a scientist runs the numbers, perhaps the outcome will be 85.2 percent. The next time, maybe it’s 93.4. Look out at the churning ocean and ask yourself exactly which whitecap is ‘sea level.’ It’s a pointless exercise at best. At worst, it’s a misleading one.
I might use that next time I teach.
The description of how academics hunt for data is also spot on: “Data sets move through the research community like yeti—I have a bunch of interesting stuff but I can’t say from where; I heard someone at Temple has tons of Amazon reviews; I think L has a scrape of Facebook.”
Sorry I didn’t take many notes this time, but Alberto Cairo’s post on the book links to a few more detailed reviews.


 ,
,  ,
,  , and
, and 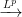 all differ, and why it matters. We saw these concepts last semester in Intermediate Statistics, but the distinctions are far clearer to me now.
all differ, and why it matters. We saw these concepts last semester in Intermediate Statistics, but the distinctions are far clearer to me now.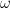 of the set
of the set 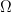 of all possible outcomes or states of the world, to the measurement you will collect (often a number on the real line). Finally, this measure theory view of probability, as the size of a subset of
of all possible outcomes or states of the world, to the measurement you will collect (often a number on the real line). Finally, this measure theory view of probability, as the size of a subset of