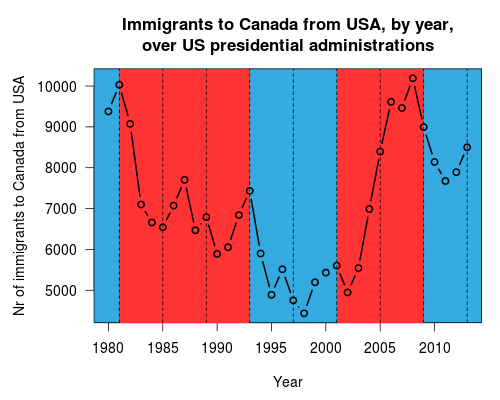
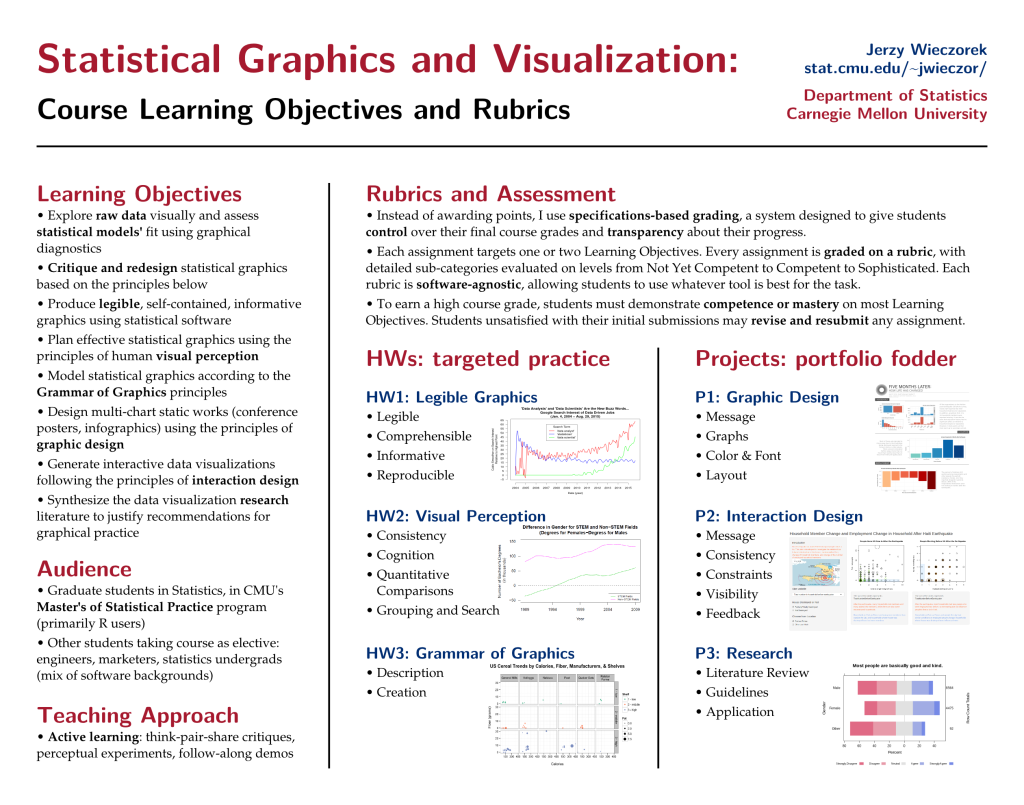
The president of the American Statistical Association, Jessica Utts, is speaking tonight at the Pittsburgh ASA Chapter meeting. She stopped by CMU first and had lunch with us grad students here.

First of all, I recommend reading Utts’ Comment on statistical computing, published 30 years ago. She mentioned a science-fiction story idea about a distant future (3 decades later, i.e. today!) in which statisticians are forgotten because everyone blindly trusts the black-box algorithm into which we feed our data. Of course, at some point in the story, it fails dramatically and a retired statistician has to save the day.
Utts gave good advice on avoiding that dystopian future, although some folks are having fun trying to implement it today—see for example The Automatic Statistician.
In some ways, I think that this worry (of being replaced by a computer) should be bigger in Machine Learning than in Statistics. Or, perhaps, ML has turned this threat into a goal. ML has a bigger culture of Kaggle-like contests: someone else provides data, splits it into training & test sets, asks a specific question (prediction or classification), and chooses a specific evaluation metric (percent correctly classified, MSE, etc.) David Donoho’s “50 years of Data Science” paper calls this the Common Task Framework (CTF). Optimizing predictions within this framework is exactly the thing that an Automatic Statistician could, indeed, automate. But the most interesting parts are the setup and interpretation of a CTF—understanding context, refining questions, designing data-collection processes, selecting evaluation metrics, interpreting results… All those fall outside the narrow task that Kaggle/CTF contestants are given. To me, such setup and interpretation are closer to the real heart of statistics and of using data to learn about the world. It’s usually nonsensical to even imagine automating them.
Besides statistical computing, Utts has worked on revamping statistics education more broadly. You should read her rejoinder to George Cobb’s article on rethinking the undergrad stats curriculum.
Utts is also the Chief Reader for grading the AP Statistics exams. AP Stats may need to change too, just as the undergraduate stats curriculum is changing… but it’s a much slower process, partly because high school AP Stats teachers aren’t actually trained in statistics the way that college and university professors are. There are also issues with computer access: even as colleges keep moving towards computer-intensive methods, in practice it remains difficult for AP Stats to assess fairly anything that can’t be done on a calculator.
Next, Utts told us that the recent ASA statement on p-values was inspired as a response to the psychology journal, BASP, that banned them. I think it’s interesting that the statement is only on p-values, even though BASP actually banned all statistical inference. Apparently it was difficult enough to get consensus on what to say about p-values alone, without agreeing on what to say about alternatives (e.g. publishing intervals, Bayesian inference, etc.) and other related statistical concepts (especially power).
Finally, we had a nice discussion about the benefits of joining the ASA: networking, organizational involvement (it’s good professional experience and looks good on your CV), attending conferences, joining chapters and sections, getting the journals… I learned that the ASA website also has lesson plans and teaching ideas, which seems quite useful. National membership is only $18 a year for students, and most local chapters or subject-matter sections are cheap or free.
The ASA has also started a website Stats.org for helping journalists understand, interpret, and report on statistical issues or analyses. If you know a journalist, tell them about this resource. If you’re a statistician willing to write some materials for the site, or to chat with journalists who have questions, go sign up.