Nathan Uyttendaele has written a great beginner’s guide to speeding up your R code. Abstract:
Most calculations performed by the average R user are unremarkable in the sense that nowadays, any computer can crush the related code in a matter of seconds. But more and more often, heavy calculations are also performed using R, something especially true in some fields such as statistics. The user then faces total execution times of his codes that are hard to work with: hours, days, even weeks. In this paper, how to reduce the total execution time of various codes will be shown and typical bottlenecks will be discussed. As a last resort, how to run your code on a cluster of computers (most workplaces have one) in order to make use of a larger processing power than the one available on an average computer will also be discussed through two examples.
Unlike many similar guides I’ve seen, this really is aimed at a computing novice. You don’t need to be a master of the command line or a Linux expert (Windows and Mac are addressed too). You are walked through installation of helpful non-R software. There’s even a nice summary of how hardware (hard drives vs RAM vs CPU) all interact to affect your code’s speed. The whole thing is 60 pages, but it’s a quick read, and even just skimming it will probably benefit you.
Favorite parts:
- “The strategy of opening R several times and of breaking down the calculations across these different R instances in order to use more than one core at the same time will also be explored (this strategy is very effective!)” I’d never realized this is possible. He gives some nice advice on how to do it with a small number of R instances (sort of “by hand,” but semi-automated).
- I knew about rm(myLargeObject), but not about needing to run gc() afterwards.
- I haven’t used Rprof before, but now I will.
- There’s helpful advice on how to get started combining C code with R under Windows—including what to install and how to set up the computer.
- The doSMP package sounds great — too bad it’s been removed 🙁 but I should practice using the parallel and snow packages.
- P.63 has a helpful list of questions to ask when you’re ready to learn using your local cluster.
One thing Uyttendaele could have mentioned, but didn’t, is the use of databases and SQL. These can be used to store really big datasets and pass small pieces of them into R efficiently, instead of loading the whole dataset into RAM at once. Anthony Damico recommends the column-store database system MonetDB and has a nice introduction to using MonetDB with survey data in R.
 ,
,  ,
,  , and
, and 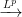 all differ, and why it matters. We saw these concepts last semester in Intermediate Statistics, but the distinctions are far clearer to me now.
all differ, and why it matters. We saw these concepts last semester in Intermediate Statistics, but the distinctions are far clearer to me now.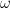 of the set
of the set 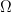 of all possible outcomes or states of the world, to the measurement you will collect (often a number on the real line). Finally, this measure theory view of probability, as the size of a subset of
of all possible outcomes or states of the world, to the measurement you will collect (often a number on the real line). Finally, this measure theory view of probability, as the size of a subset of