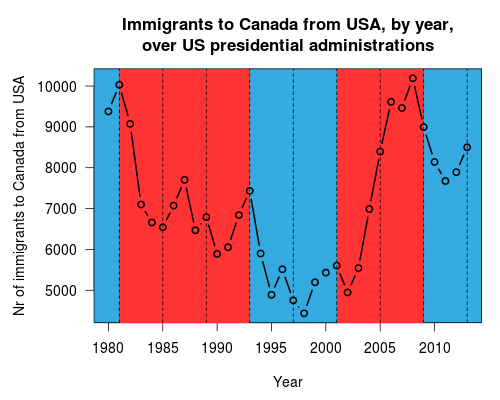
I am saddened to hear that Lee Wilkinson passed away a few days ago. Wilkinson created the hugely influential concept of a “Grammar of Graphics” and wrote it up in a thorough, thought-provoking book. Through his writings and his own entrepreneurial spirit (he started SYSTAT and sold it to SPSS, then worked with Tableau and H20.ai among others), the Grammar of Graphics became a hugely influential idea1, adopted in many powerful data visualization software packages—Tableau, R’s ggplot2, Python’s plotnine, Javascript’s D3.js and Vega, the SPSS Graphics Production Language (GPL) and Visualization Designer, IBM VizJSON…

Wilkinson was supposed to speak at a Data Visualization New York meetup tomorrow; instead, it has become a memorial tribute session. The event is online and open to all. Meanwhile, I have seen heartfelt tributes to Wilkinson from a who’s who of the data visualization world: Hadley Wickham (developer of ggplot2), Nathan Yau (creator of FlowingData), Jessica Hullman (prolific dataviz researcher), Jon Schwabish (creator of PolicyViz), Jeff Heer (developer of D3.js and Vega)… Everyone reiterates that he was not only an influential scholar, but also a generous, kind, decent human being.
Apart from his visualization work, I loved Wilkinson’s voice in a report written mostly by him on behalf of the American Psychological Association’s 1999 Task Force on Statistical Inference. Here’s the note I wrote myself when I first ran across this report, and I still stand by it:
This is a really great, short, but fairly complete overview of major components in a statistical study...
i.e., the things you want your junior statistician colleague to know without being told...
i.e., the things we ought to teach AND MEASURE ON our stats students.
Two of my favorite quotes from that report:
“Statistical power does not corrupt.”
and
The main point of this example is that the type of “atheoretical” search for patterns that we are sometimes warned against in graduate school can save us from the humiliation of having to retract conclusions we might ultimately make on the basis of contaminated data. We are warned against fishing expeditions for understandable reasons, but blind application of models without screening our data is a far graver error.
I had the incredible good fortune of meeting Wilkinson myself at a conference, though regrettably just once. This was SDSS 2019 in Seattle—the last conference I attended in person before the pandemic. One groggy morning, I stepped away from my conference breakfast table to get a second cup of coffee. I came back to find that Wilkinson had just sat down, thinking the table was empty. We ended up having a genuinely delightful conversation. I asked how he had managed to combine so many fascinating strands of work in his career, and he told me it had been a roundabout path: if I remember correctly, he had dropped his math major in his first week of college and switched to English; then later dropped out of divinity school; then just barely finished Psychology graduate school because he couldn’t stop tinkering with computers instead; then became a statistical software entrepreneur… He also reminisced fondly about attending conferences as a young researcher, where he got to hear giants in the field get drunk at the open bar and tell their life story 😛 Wilkinson was a witty and warm conversation partner. After breakfast he invited me to keep in touch, and I deeply regret that I never followed up. Rest in peace, Leland Wilkinson.